The internet is one of the most impactful technologies of today, enabling billions of people to communicate with family members around the globe, to share photos with one another, and to collaboratively edit documents in real time. Most of these systems are built on cloud architectures where centralized servers store user information and synchronize that data across user devices. The image below illustrates how this architecture typically works. When a user makes an edit on their laptop, the update is sent to a trusted third party server which synchronizes the data and forwards it to another user's cell phone.
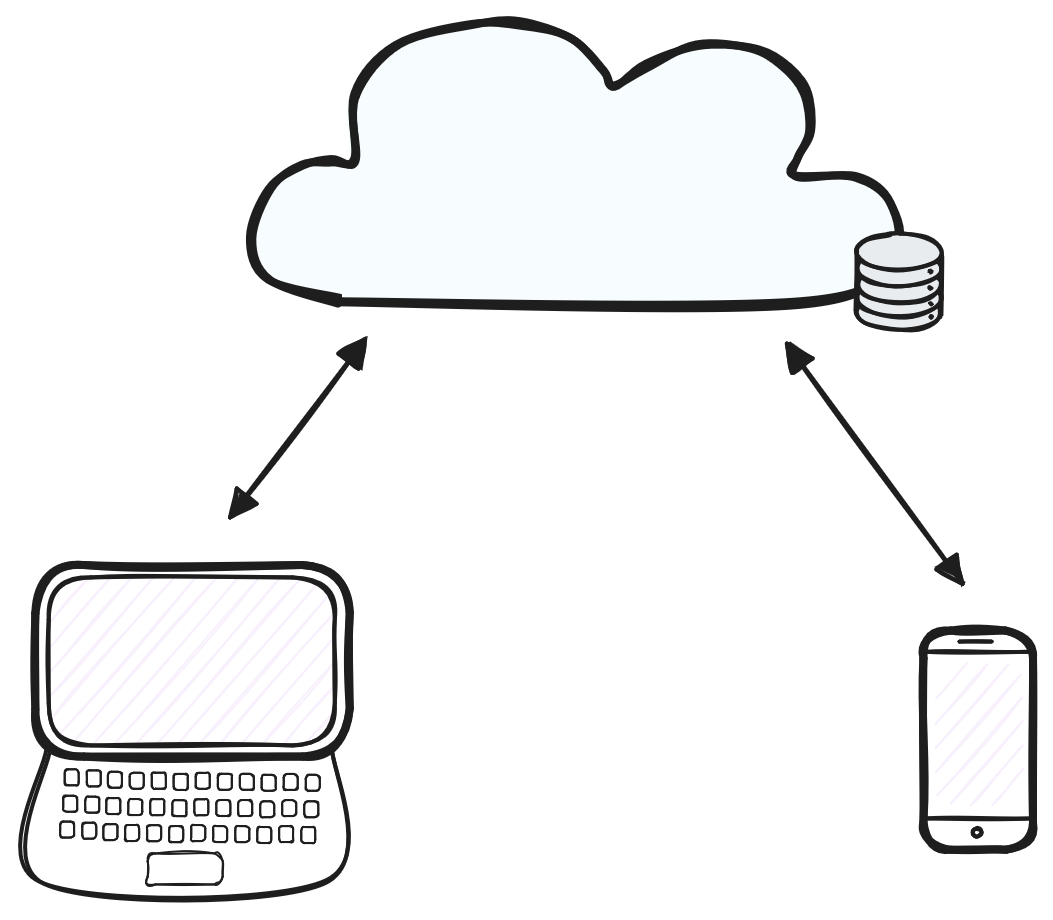
A traditional cloud architecture.
In the cloud setting, we depend on third party servers to protect our data and make sure that it is available when we need to access it. These cloud services are fairly reliable, however they do not always succeed in these tasks. Oftentimes user data is not encrypted which can lead to large data breaches where attackers gain access to personally identifiable information, financial information, location logs, chat messages, shared photos, and proprietary documents for all users on a website. Some sites directly sell user information to third parties for advertising revenue while others manipulate the content that is presented to users. Websites also go down and users lose internet connections like while traveling on planes. In these situations, users cannot edit their documents that are stored in the cloud. When large sites are offline, billions of users are impacted and prevented from accessing their documents while servers are unavailable. These are some of the downsides of the web today, but can we do better? Do we need to trust third party services with our data?
Recent advances in distributed systems and cryptography open up the possibility of improving the state of the web by shifting away from cloud architectures. In particular, these advances enable decentralized architectures which eliminate the reliance on centralized servers and give users back control over their data. The following image depicts what a decentralized architecture would look like.
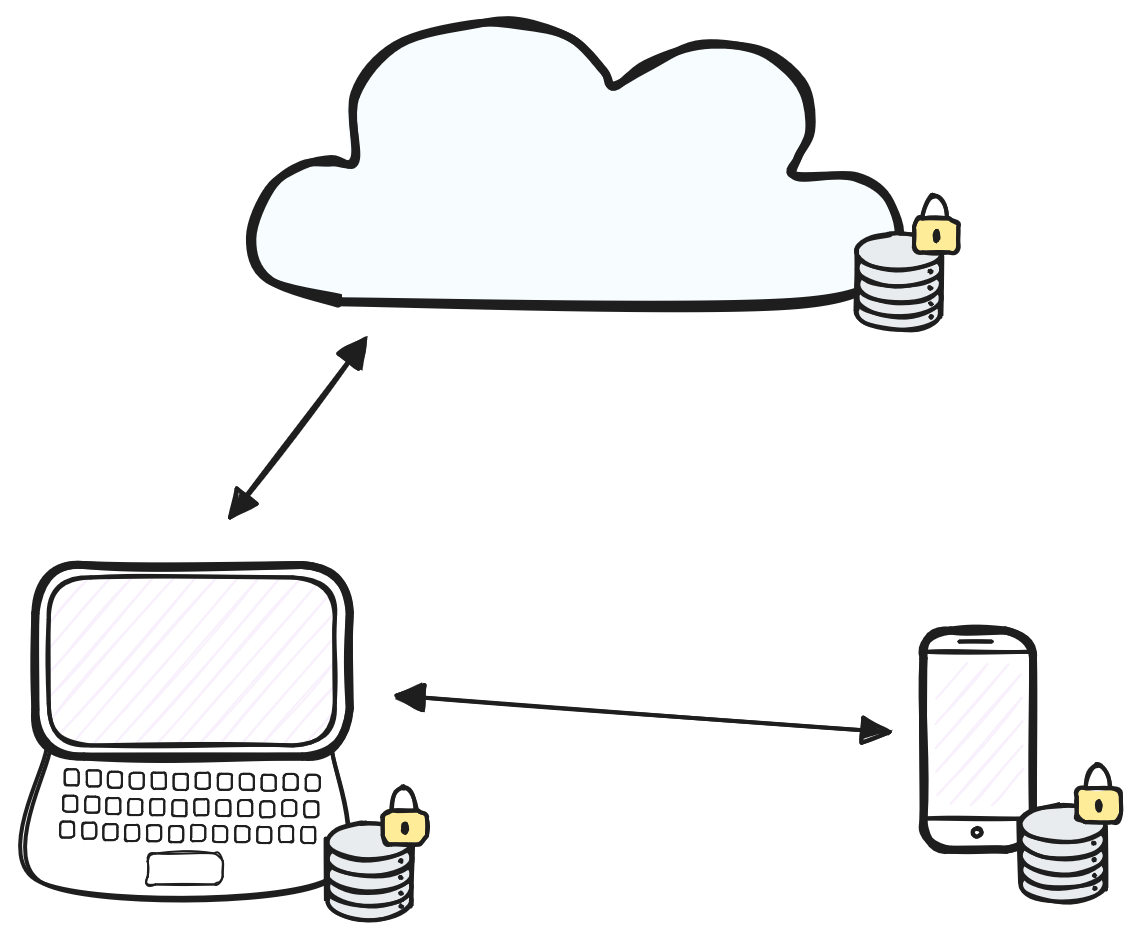
The next generation decentralized web architecture.
In this architecture, users no longer rely on third party servers to store and synchronize updates between their devices. Instead, user devices directly connect to one another over peer-to-peer network connections. Devices are able to directly share and synchronize updates between one another. Furthermore, data is stored locally on user devices so users can now access and edit their data even while offline. When connections are restored, updates are automatically synchronized between peers. All data can be end-to-end encrypted so that users are only able to read what they have permission to access. In this setting, cloud servers are no longer required, but they can still be used to keep encrypted backups and forward updates to user devices.
Introducing Ossa
The Ossa Protocol is a secure, decentralized local-first synchronization protocol. The protocol lays the foundation for the next generation web where collaborative web applications are built on the decentralized web architecture previously described. In addition, the protocol is local-first since it realizes the vision proposed by Kleppmann et al. where users securely and collaboratively control their data.
The Ossa Protocol defines the underlying networking and cryptographic functionality so that developers can easily build secure, collaborative decentralized web applications. Key features of the protocol are that connections are peer-to-peer between end user devices, all data is end-to-end encrypted, users and groups have fine grained access control over their documents, and the protocol is secure against Byzantine actors.
An early prototype implementation of the Ossa Protocol is open source and available on Github. Currently only a subset of the protocol is implemented, but enough is complete to build demo applications. Note that most security features are not implemented yet and the protocol will change so it is not ready for production deployments. The video below shows a simple demo application built using Ossa.
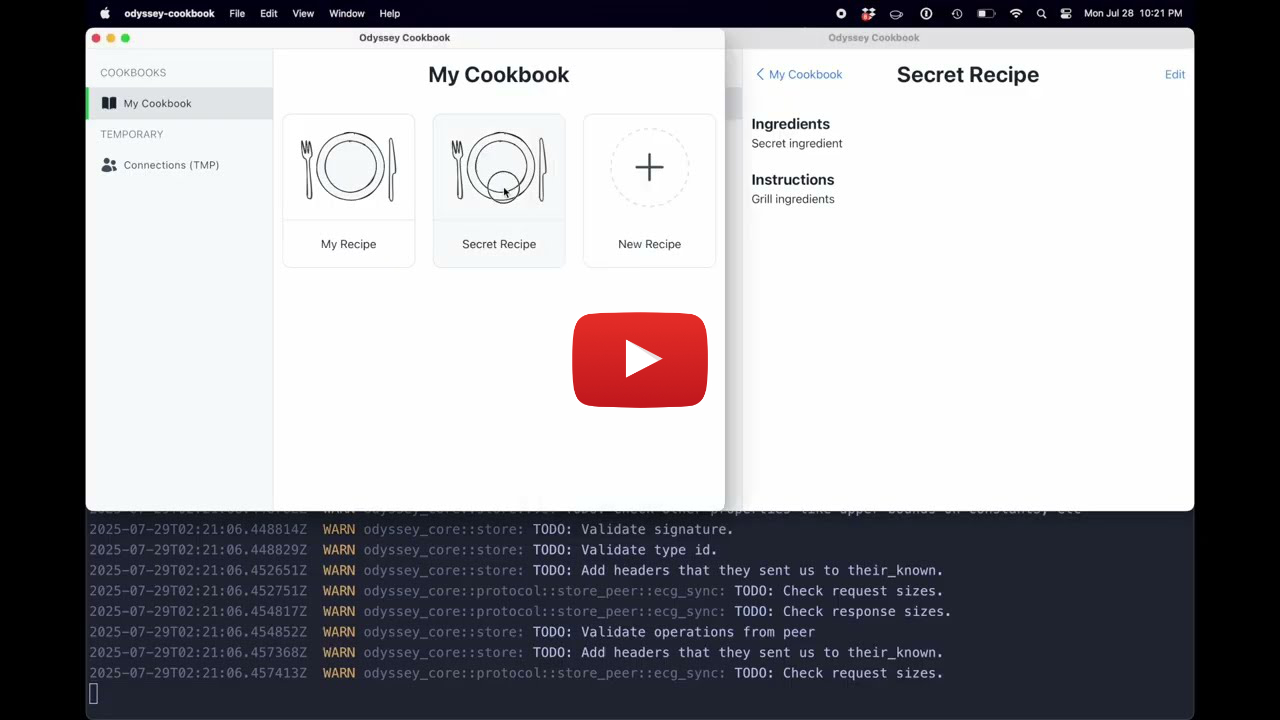
Demo recipe application built with Ossa.
This demo application allows users to create recipe cookbooks that can be shared and collaboratively edited by other users. In the video, Alice creates a new cookbook and shares it with Bob. Bob connects to Alice and then joins the cookbook. Alice and Bob both make edits to the cookbook by adding and modifying recipes. Note that there is no central server that is synchronizing updates. Each party is making edits that are sent directly to the other person.
Technical overview
The rest of this post provides a high level technical overview of how the Ossa Protocol works. Future blog posts will go into more detail about different parts of the protocol and will provide updates as the rest of the protocol is implemented.
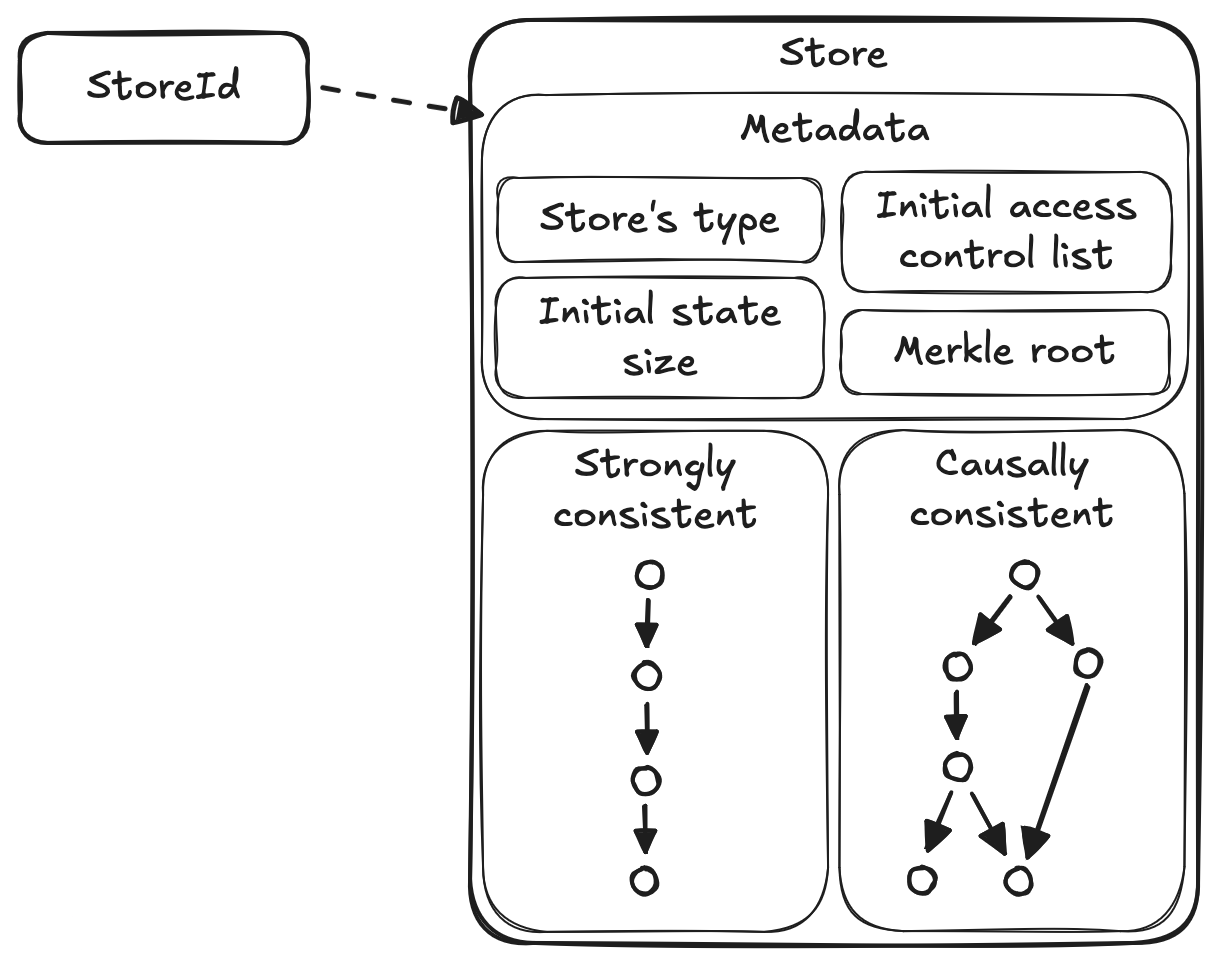
Components of a store.
Stores are the core building block of Ossa that allow decentralized applications to save and synchronize state across multiple devices.
The diagram above depicts the components of a store.
The first part of a store is its metadata which includes the type of the store's data, the initial access control list to access the store, the size of the store's initial state, and the merkle root of the store's (potentially encrypted) initial state.
A store's identity (or StoreId) is a unique identifier that is obtained by hashing the store's metadata.
This makes stores content addressable.
As a result, peers can access a store in a decentralized manner by looking up its StoreId in a distributed hash table (DHT).
Stores are polymorphic since their state can hold any type of data that the application requires.
Most applications will utilize multiple stores and types of stores.
For example, the demo cookbook recipe application has multiple Cookbook stores while a photo application might have many Album stores and Photo stores.
One restriction on a store's type is that it must be a Conflict-free replicated data type (CRDT).
This is necessary to
synchronize concurrent updates made on end user devices without a central server
and to allow users to make edits while offline.
The causally consistent component of a store maintains all of the updates that users make to the store's state. Specifically, all of the updates are batched CRDT operations that are digitally signed and end-to-end encrypted. In order to preserve causal consistency, updates form a partial order materialized as a directed acyclic graph (DAG). Each update is uniquely identified by hashing the update, similar to commits in git or as described by Kleppmann in the paper "Making CRDTs Byzantine fault tolerant".
The final component of a store offers strong consistency. Here we rely on an asynchronous byzantine fault tolerant consensus protocol to reach agreement between a store's authorized devices to establish a total order on updates that require linearizability. Such updates include modifying the store's access control list, snapshotting the current state by referencing the tips of the causal consistency graph, and applying version updates as the application's software is upgraded. The main reason for this strongly consistent component is the following: I hypothesize that it is impossible to securely implement access control in a manner that matches user's expectations in a decentralized setting with only causal consistency. If this hypothesis is true, strong consistency is required to provide a total order to achieve secure access control.
This post has introduced the Ossa Protocol as the foundation for the next generation web that shifts away from centralized cloud architectures towards decentralized, local-first architectures. If you have any feedback or are interested in collaborating on the protocol, please reach out!
Note: This post has been crossposted to Ossa's blog.